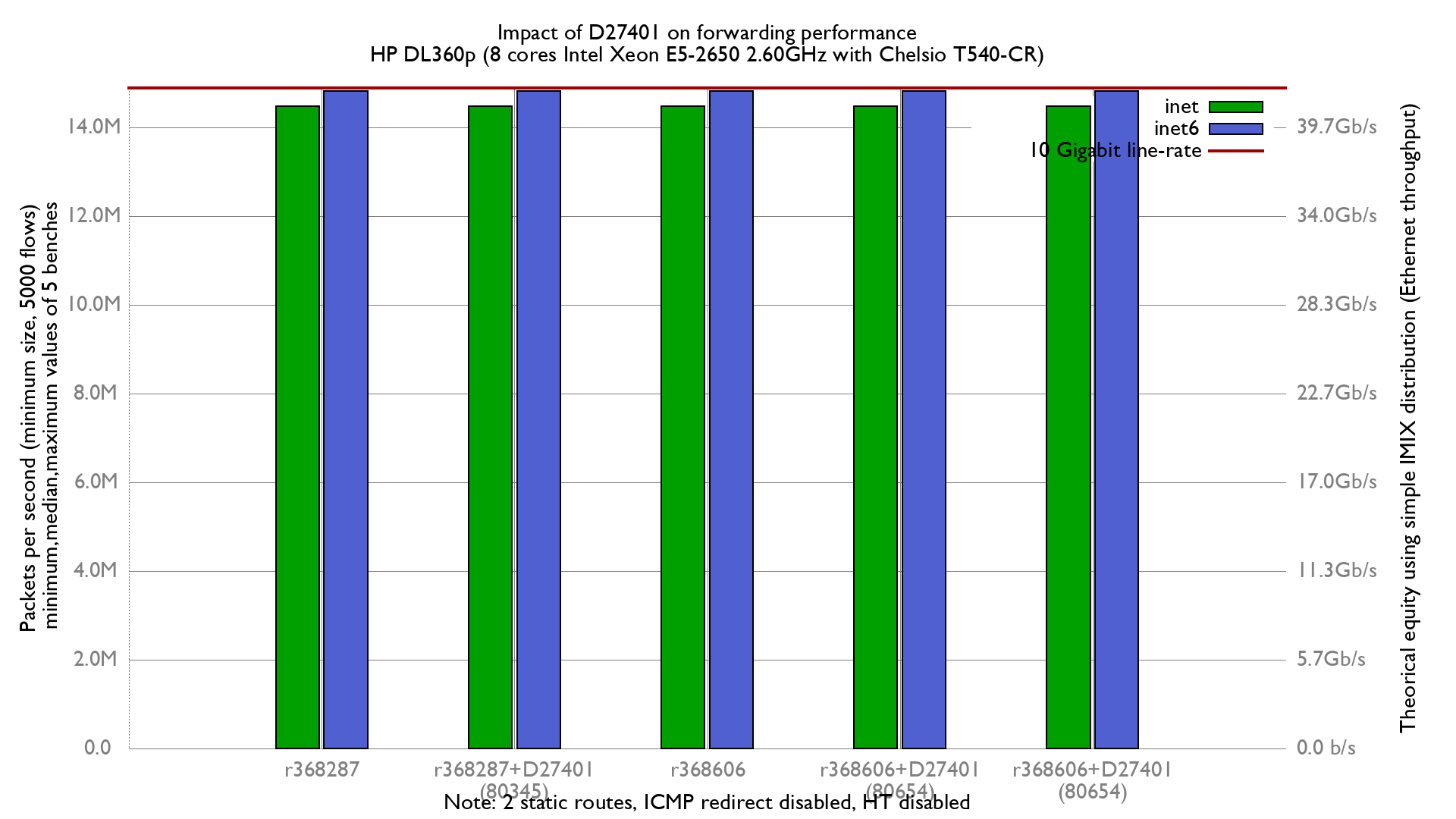
Problem statement
Currently FreeBSD uses radix (compressed binary tree) to perform all unicast route manipulations including loookups.
Radix requires storing key length in each item, allowing to use sockaddrs and literally any address family.
This flexibility comes at the cost: radix is slow, cache-unfriendly and adds locking to the hot path.
There is an extremely high bar in trying to switch radix to something else.
Some efforts has been done to reduce the coupling, however radix is still closely tied to the rest of the system. Fixed locking semantics, rtentry format, iteration assumptions prevents restrict the list of possible solutions.
Algo overview
For small tables (VM, potentially embedded), class of read-only datastructures can be used, as it is easy to rebuild the entire datastructure from scratch on each change.
For large tables, there are far more effective algorithms tailored for IPv4 and IPv6 lookups. Algorithms like DIR24-8, Lulea or DXR use 3-5 bytes per prefix, compared to ~192 bytes in radix for large-table use cases.
They also limit lookup to 2-3 memory accesses (IPv4), while radix can be notably worse.
Some of the algorithms require complex update procedures, so using them assumes some sort of update batching to reduce the change overhead.
Goals
- Reduce the bar in introducing new route lookup algorithms
- Make existing routing lookups for existing families fast and lockless
Proposed solution
Add a framework that allows to attach lookup algorithms via kernel modules, allowing them to be used for dataplane LPM lookups.
As most of the effective algorithms perform one-way compilation of prefixes into custom data structures, their implementations rely on another "control-plane" copy of the prefixes to perform datastructure updates. This approach keeps radix as the “control plane” source of truth, simplifying the actual algorithm implementation. It also serves as the abstraction layer for the current routing code details such as requirements on lock ordering or control plane performance.
Algorithms
As a baseline, the following algorithms will be provided out of the box:
IPv4:
- lockless radix (small amount of routes, rebuilding on each change, in-kernel)
- DPDK rte lpm (DIR24-8 variation, large-tables, kernel-module) (D27412)
- "base" radix (to serve as a fallback, in-kernel)
IPv6:
- lockless radix (small amount of routes, rebuilding on each change, in-kernel)
- DPDK rte lpm (DIR24-8 variation, large-tables, kernel-module) (D27412)
- "base" radix (to serve as a fallback, in-kernel)
Implementation details
Framework takes care of handling initial synchronisation, route subscription, nhop/nhop groups reference and indexing, dataplane attachments and fib instance algorithm setup/teardown.
Retries
Framework is build to be resilient about failures. It explicitly allows algorithms to request "rebuild" if an algorithm is unable to perform in-place modification. For example, it is possible that memory allocation fails or algorithm/framework runs of object indexes.
Rebuild is simply building new algorithm instance, potentially fetching data from an old instance and switching dataplane pointers.
This approach simplifies implementation of readonly datastructures and update batching.
Automatic algorithm selection
As different workloads may have different route scale, including the framework in GENERIC requires supporting all scales w/o human intervention. Framework implements automatic algorithm selection and switchover the following way:
- each algo has get_preference() callback, returning relative preference (0..255) for the provided route table scale
- after routing table change, callback is scheduled to re-evaluate currently used algorithm vs others. Callback executes after N=30 sec or M=100 route changes, whichever happens first
- New algorithm preference has to be X=5% better than the current one to enable switchover
Nexthop referencing and indexing
Framework provide wrappers to automatically reference nexthops, ensuring they can be safely returned and their refcount is non-zero.
It also maintains idx->nhop pointer array, transparently handling nhop/nhop group indexes, allowing algorithms to store 16 or 32-bit indexes instead of pointers.
Dataplane pointers
Instead of two-dimensional rnh array operated by`rt_table_get_rnh()`, framework uses per-family linear array of the following structures:
struct fib_dp {
flm_lookup_t *f;
void *arg;
};Function is the algorithm lookup function and the data is the pointer to the algorithm-specific data structure.
Changing the function/data pointer is implemented by creating another array copy, switching it and reclaiming old copy via epoch(9) callback.
Callbacks
Effectively the lookup module needs to implement 6 callbacks, with nearly all of table interaction is handled by the framework:
# Lookup: return nexthop pointer for address specified by key and scopeid
typedef struct nhop_object *flm_lookup_t(void *algo_data,
const struct flm_lookup_key key, uint32_t scopeid);
# Create base datastructures for the instance tied to a specific RIB
typedef enum flm_op_result flm_init_t (uint32_t fibnum, struct fib_data *fd,
void *_old_data, void **new_data);
# Free algorithm-specific datastructures
typedef void flm_destroy_t(void *data);
# Callback for initial synchronisation, called for each route in the routing table as a part of "rebuild"
# called under rib write lock
typedef enum flm_op_result flm_dump_t(struct rtentry *rt, void *data);
# Callback for providing the datapath func/pointer to be used in lookups
# called under rib write lock
typedef enum flm_op_result flm_dump_end_t(void *data, struct fib_dp *dp);
# Callback notifying of a single route table change
# called under rib write lock
typedef enum flm_op_result flm_change_t(struct rib_head *rnh,
struct rib_cmd_info *rc, void *data);
# Callback for determining relative algorithm preference based on the routing table data
typedef uint8_t flm_get_pref_t(const struct rib_rtable_info *rinfo);